
DESCRIPTION top grep searches for PATTERNS in each FILE. PATTERNS is one or more patterns separated by newline characters, and grep prints each line that matches a pattern. Typically PATTERNS should be quoted when grep is used in a shell command. A FILE of “-” stands for standard input. If no FILE is given, recursive searches examine the working directory, and nonrecursive searches read standard input.
OPTIONS top Generic Program Information --help Output a usage message and exit. -V, --version Output the version number of grep and exit. Pattern Syntax -E, --extended-regexp Interpret PATTERNS as extended regular expressions (EREs, see below). -F, --fixed-strings Interpret PATTERNS as fixed strings, not regular expressions. -G, --basic-regexp Interpret PATTERNS as basic regular expressions (BREs, see below). This is the default. -P, --perl-regexp Interpret PATTERNS as Perl-compatible regular expressions (PCREs). This option is experimental when combined with the -z (--null-data) option, and grep -P may warn of unimplemented features.
Matching Control -e PATTERNS, --regexp=PATTERNS Use PATTERNS as the patterns. If this option is used multiple times or is combined with the -f (--file) option, search for all patterns given. This option can be used to protect a pattern beginning with “-”. -f FILE, --file=FILE Obtain patterns from FILE, one per line. If this option is used multiple times or is combined with the -e (--regexp) option, search for all patterns given. The empty file contains zero patterns, and therefore matches nothing. -i, --ignore-case Ignore case distinctions in patterns and input data, so that characters that differ only in case match each other. --no-ignore-case Do not ignore case distinctions in patterns and input data. This is the default. This option is useful for passing to shell scripts that already use -i, to cancel its effects because the two options override each other. -v, --invert-match Invert the sense of matching, to select non-matching lines. -w, --word-regexp Select only those lines containing matches that form whole words. The test is that the matching substring must either be at the beginning of the line, or preceded by a non-word constituent character. Similarly, it must be either at the end of the line or followed by a non-word constituent character. Word-constituent characters are letters, digits, and the underscore. This option has no effect if -x is also specified. -x, --line-regexp Select only those matches that exactly match the whole line. For a regular expression pattern, this is like parenthesizing the pattern and then surrounding it with ^ and $.
General Output Control -c, --count Suppress normal output; instead print a count of matching lines for each input file. With the -v, --invert-match option (see above), count non-matching lines. --color[=WHEN], --colour[=WHEN] Surround the matched (non-empty) strings, matching lines, context lines, file names, line numbers, byte offsets, and separators (for fields and groups of context lines) with escape sequences to display them in color on the terminal. The colors are defined by the environment variable GREP_COLORS. WHEN is never, always, or auto. -L, --files-without-match Suppress normal output; instead print the name of each input file from which no output would normally have been printed. -l, --files-with-matches Suppress normal output; instead print the name of each input file from which output would normally have been printed. Scanning each input file stops upon first match. -m NUM, --max-count=NUM Stop reading a file after NUM matching lines. If NUM is zero, grep stops right away without reading input. A NUM of -1 is treated as infinity and grep does not stop; this is the default. If the input is standard input from a regular file, and NUM matching lines are output, grep ensures that the standard input is positioned to just after the last matching line before exiting, regardless of the presence of trailing context lines. This enables a calling process to resume a search. When grep stops after NUM matching lines, it outputs any trailing context lines. When the -c or --count option is also used, grep does not output a count greater than NUM. When the -v or --invert-match option is also used, grep stops after outputting NUM non-matching lines. -o, --only-matching Print only the matched (non-empty) parts of a matching line, with each such part on a separate output line. -q, --quiet, --silent Quiet; do not write anything to standard output. Exit immediately with zero status if any match is found, even if an error was detected. Also see the -s or --no-messages option. -s, --no-messages Suppress error messages about nonexistent or unreadable files. Output Line Prefix Control -b, --byte-offset Print the 0-based byte offset within the input file before each line of output. If -o (--only-matching) is specified, print the offset of the matching part itself. -H, --with-filename Print the file name for each match. This is the default when there is more than one file to search. This is a GNU extension. -h, --no-filename Suppress the prefixing of file names on output. This is the default when there is only one file (or only standard input) to search. --label=LABEL Display input actually coming from standard input as input coming from file LABEL. This can be useful for commands that transform a file's contents before searching, e.g., gzip -cd foo.gz | grep --label=foo -H 'some pattern'. See also the -H option. -n, --line-number Prefix each line of output with the 1-based line number within its input file. -T, --initial-tab Make sure that the first character of actual line content lies on a tab stop, so that the alignment of tabs looks normal. This is useful with options that prefix their output to the actual content: -H,-n, and -b. In order to improve the probability that lines from a single file will all start at the same column, this also causes the line number and byte offset (if present) to be printed in a minimum size field width. -Z, --null Output a zero byte (the ASCII NUL character) instead of the character that normally follows a file name. For example, grep -lZ outputs a zero byte after each file name instead of the usual newline. This option makes the output unambiguous, even in the presence of file names containing unusual characters like newlines. This option can be used with commands like find -print0, perl -0, sort -z, and xargs -0 to process arbitrary file names, even those that contain newline characters.
Context Line Control -A NUM, --after-context=NUM Print NUM lines of trailing context after matching lines. Places a line containing a group separator (--) between contiguous groups of matches. With the -o or --only-matching option, this has no effect and a warning is given. -B NUM, --before-context=NUM Print NUM lines of leading context before matching lines. Places a line containing a group separator (--) between contiguous groups of matches. With the -o or --only-matching option, this has no effect and a warning is given. -C NUM, -NUM, --context=NUM Print NUM lines of output context. Places a line containing a group separator (--) between contiguous groups of matches. With the -o or --only-matching option, this has no effect and a warning is given. --group-separator=SEP When -A, -B, or -C are in use, print SEP instead of -- between groups of lines. --no-group-separator When -A, -B, or -C are in use, do not print a separator between groups of lines. File and Directory Selection -a, --text Process a binary file as if it were text; this is equivalent to the --binary-files=text option. --binary-files=TYPE If a file's data or metadata indicate that the file contains binary data, assume that the file is of type TYPE. Non-text bytes indicate binary data; these are either output bytes that are improperly encoded for the current locale, or null input bytes when the -z option is not given. By default, TYPE is binary, and grep suppresses output after null input binary data is discovered, and suppresses output lines that contain improperly encoded data. When some output is suppressed, grep follows any output with a message to standard error saying that a binary file matches. If TYPE is without-match, when grep discovers null input binary data it assumes that the rest of the file does not match; this is equivalent to the -I option. If TYPE is text, grep processes a binary file as if it were text; this is equivalent to the -a option. When type is binary, grep may treat non-text bytes as line terminators even without the -z option. This means choosing binary versus text can affect whether a pattern matches a file. For example, when type is binary the pattern q$ might match q immediately followed by a null byte, even though this is not matched when type is text. Conversely, when type is binary the pattern . (period) might not match a null byte. Warning: The -a option might output binary garbage, which can have nasty side effects if the output is a terminal and if the terminal driver interprets some of it as commands. On the other hand, when reading files whose text encodings are unknown, it can be helpful to use -a or to set LC_ALL='C' in the environment, in order to find more matches even if the matches are unsafe for direct display. -D ACTION, --devices=ACTION If an input file is a device, FIFO or socket, use ACTION to process it. By default, ACTION is read, which means that devices are read just as if they were ordinary files. If ACTION is skip, devices are silently skipped. -d ACTION, --directories=ACTION If an input file is a directory, use ACTION to process it. By default, ACTION is read, i.e., read directories just as if they were ordinary files. If ACTION is skip, silently skip directories. If ACTION is recurse, read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -r option. --exclude=GLOB Skip any command-line file with a name suffix that matches the pattern GLOB, using wildcard matching; a name suffix is either the whole name, or a trailing part that starts with a non-slash character immediately after a slash (/) in the name. When searching recursively, skip any subfile whose base name matches GLOB; the base name is the part after the last slash. A pattern can use *, ?, and [...] as wildcards, and \ to quote a wildcard or backslash character literally. --exclude-from=FILE Skip files whose base name matches any of the file-name globs read from FILE (using wildcard matching as described under --exclude). --exclude-dir=GLOB Skip any command-line directory with a name suffix that matches the pattern GLOB. When searching recursively, skip any subdirectory whose base name matches GLOB. Ignore any redundant trailing slashes in GLOB. -I Process a binary file as if it did not contain matching data; this is equivalent to the --binary-files=without-match option. --include=GLOB Search only files whose base name matches GLOB (using wildcard matching as described under --exclude). If contradictory --include and --exclude options are given, the last matching one wins. If no --include or --exclude options match, a file is included unless the first such option is --include. -r, --recursive Read all files under each directory, recursively, following symbolic links only if they are on the command line. Note that if no file operand is given, grep searches the working directory. This is equivalent to the -d recurse option. -R, --dereference-recursive Read all files under each directory, recursively. Follow all symbolic links, unlike -r. Other Options --line-buffered Use line buffering on output. This can cause a performance penalty. -U, --binary Treat the file(s) as binary. By default, under MS-DOS and MS-Windows, grep guesses whether a file is text or binary as described for the --binary-files option. If grep decides the file is a text file, it strips the CR characters from the original file contents (to make regular expressions with ^ and $ work correctly). Specifying -U overrules this guesswork, causing all files to be read and passed to the matching mechanism verbatim; if the file is a text file with CR/LF pairs at the end of each line, this will cause some regular expressions to fail. This option has no effect on platforms other than MS-DOS and MS-Windows. -z, --null-data Treat input and output data as sequences of lines, each terminated by a zero byte (the ASCII NUL character) instead of a newline. Like the -Z or --null option, this option can be used with commands like sort -z to process arbitrary file names.
REGULAR EXPRESSIONS top A regular expression is a pattern that describes a set of strings. Regular expressions are constructed analogously to arithmetic expressions, by using various operators to combine smaller expressions. grep understands three different versions of regular expression syntax: “basic” (BRE), “extended” (ERE) and “perl” (PCRE). In GNU grep there is no difference in available functionality between basic and extended syntax. In other implementations, basic regular expressions are less powerful. The following description applies to extended regular expressions; differences for basic regular expressions are summarized afterwards. Perl- compatible regular expressions give additional functionality, and are documented in pcre2syntax(3) and pcre2pattern(3), but work only if PCRE support is enabled. The fundamental building blocks are the regular expressions that match a single character. Most characters, including all letters and digits, are regular expressions that match themselves. Any meta-character with special meaning may be quoted by preceding it with a backslash. The period . matches any single character. It is unspecified whether it matches an encoding error. Character Classes and Bracket Expressions A bracket expression is a list of characters enclosed by [ and ]. It matches any single character in that list. If the first character of the list is the caret ^ then it matches any character not in the list; it is unspecified whether it matches an encoding error. For example, the regular expression [0123456789] matches any single digit. Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale's collating sequence and character set. For example, in the default C locale, [a-d] is equivalent to [abcd]. Many locales sort characters in dictionary order, and in these locales [a-d] is typically not equivalent to [abcd]; it might be equivalent to [aBbCcDd], for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C. Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are [:alnum:], [:alpha:], [:blank:], [:cntrl:], [:digit:], [:graph:], [:lower:], [:print:], [:punct:], [:space:], [:upper:], and [:xdigit:]. For example, [[:alnum:]] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as [0-9A-Za-z]. (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most meta-characters lose their special meaning inside bracket expressions. To include a literal ] place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal - place it last.
Anchoring The caret ^ and the dollar sign $ are meta-characters that respectively match the empty string at the beginning and end of a line. The Backslash Character and Special Expressions The symbols \< and \> respectively match the empty string at the beginning and end of a word. The symbol \b matches the empty string at the edge of a word, and \B matches the empty string provided it's not at the edge of a word. The symbol \w is a synonym for [_[:alnum:]] and \W is a synonym for [^_[:alnum:]]. Repetition A regular expression may be followed by one of several repetition operators: ? The preceding item is optional and matched at most once. * The preceding item will be matched zero or more times. + The preceding item will be matched one or more times. {n} The preceding item is matched exactly n times. {n,} The preceding item is matched n or more times. {,m} The preceding item is matched at most m times. This is a GNU extension. {n,m} The preceding item is matched at least n times, but not more than m times.
Concatenation Two regular expressions may be concatenated; the resulting regular expression matches any string formed by concatenating two substrings that respectively match the concatenated expressions. Alternation Two regular expressions may be joined by the infix operator |; the resulting regular expression matches any string matching either alternate expression. Precedence Repetition takes precedence over concatenation, which in turn takes precedence over alternation. A whole expression may be enclosed in parentheses to override these precedence rules and form a subexpression. Back-references and Subexpressions The back-reference \n, where n is a single digit, matches the substring previously matched by the nth parenthesized subexpression of the regular expression. Basic vs Extended Regular Expressions In basic regular expressions the meta-characters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions \?, \+, \{, \|, \(, and \). EXIT STATUS top Normally the exit status is 0 if a line is selected, 1 if no lines were selected, and 2 if an error occurred. However, if the -q or --quiet or --silent is used and a line is selected, the exit status is 0 even if an error occurred. ENVIRONMENT top The behavior of grep is affected by the following environment variables. The locale for category LC_foo is specified by examining the three environment variables LC_ALL, LC_foo, LANG, in that order. The first of these variables that is set specifies the locale. For example, if LC_ALL is not set, but LC_MESSAGES is set to pt_BR, then the Brazilian Portuguese locale is used for the LC_MESSAGES category. The C locale is used if none of these environment variables are set, if the locale catalog is not installed, or if grep was not compiled with national language support (NLS). The shell command locale -a lists locales that are currently available.
GREP_COLORS Controls how the --color option highlights output. Its value is a colon-separated list of capabilities that defaults to ms=01;31:mc=01;31:sl=:cx=:fn=35:ln=32:bn=32:se=36 with the rv and ne boolean capabilities omitted (i.e., false). Supported capabilities are as follows. sl= SGR substring for whole selected lines (i.e., matching lines when the -v command-line option is omitted, or non-matching lines when -v is specified). If however the boolean rv capability and the -v command-line option are both specified, it applies to context matching lines instead. The default is empty (i.e., the terminal's default color pair). cx= SGR substring for whole context lines (i.e., non- matching lines when the -v command-line option is omitted, or matching lines when -v is specified). If however the boolean rv capability and the -v command-line option are both specified, it applies to selected non-matching lines instead. The default is empty (i.e., the terminal's default color pair). rv Boolean value that reverses (swaps) the meanings of the sl= and cx= capabilities when the -v command- line option is specified. The default is false (i.e., the capability is omitted). mt=01;31 SGR substring for matching non-empty text in any matching line (i.e., a selected line when the -v command-line option is omitted, or a context line when -v is specified). Setting this is equivalent to setting both ms= and mc= at once to the same value. The default is a bold red text foreground over the current line background. ms=01;31 SGR substring for matching non-empty text in a selected line. (This is only used when the -v command-line option is omitted.) The effect of the sl= (or cx= if rv) capability remains active when this kicks in. The default is a bold red text foreground over the current line background. mc=01;31 SGR substring for matching non-empty text in a context line. (This is only used when the -v command-line option is specified.) The effect of the cx= (or sl= if rv) capability remains active when this kicks in. The default is a bold red text foreground over the current line background. fn=35 SGR substring for file names prefixing any content line. The default is a magenta text foreground over the terminal's default background. ln=32 SGR substring for line numbers prefixing any content line. The default is a green text foreground over the terminal's default background. bn=32 SGR substring for byte offsets prefixing any content line. The default is a green text foreground over the terminal's default background. se=36 SGR substring for separators that are inserted between selected line fields (:), between context line fields, (-), and between groups of adjacent lines when nonzero context is specified (--). The default is a cyan text foreground over the terminal's default background. ne Boolean value that prevents clearing to the end of line using Erase in Line (EL) to Right (\33[K) each time a colorized item ends. This is needed on terminals on which EL is not supported. It is otherwise useful on terminals for which the back_color_erase (bce) boolean terminfo capability does not apply, when the chosen highlight colors do not affect the background, or when EL is too slow or causes too much flicker. The default is false (i.e., the capability is omitted). Note that boolean capabilities have no =... part. They are omitted (i.e., false) by default and become true when specified. See the Select Graphic Rendition (SGR) section in the documentation of the text terminal that is used for permitted values and their meaning as character attributes. These substring values are integers in decimal representation and can be concatenated with semicolons. grep takes care of assembling the result into a complete SGR sequence (\33[...m). Common values to concatenate include 1 for bold, 4 for underline, 5 for blink, 7 for inverse, 39 for default foreground color, 30 to 37 for foreground colors, 90 to 97 for 16-color mode foreground colors, 38;5;0 to 38;5;255 for 88-color and 256-color modes foreground colors, 49 for default background color, 40 to 47 for background colors, 100 to 107 for 16-color mode background colors, and 48;5;0 to 48;5;255 for 88-color and 256-color modes background colors. LC_ALL, LC_COLLATE, LANG These variables specify the locale for the LC_COLLATE category, which determines the collating sequence used to interpret range expressions like [a-z]. LC_ALL, LC_CTYPE, LANG These variables specify the locale for the LC_CTYPE category, which determines the type of characters, e.g., which characters are whitespace. This category also determines the character encoding, that is, whether text is encoded in UTF-8, ASCII, or some other encoding. In the C or POSIX locale, all characters are encoded as a single byte and every byte is a valid character. LC_ALL, LC_MESSAGES, LANG These variables specify the locale for the LC_MESSAGES category, which determines the language that grep uses for messages. The default C locale uses American English messages. POSIXLY_CORRECT If set, grep behaves as POSIX requires; otherwise, grep behaves more like other GNU programs. POSIX requires that options that follow file names must be treated as file names; by default, such options are permuted to the front of the operand list and are treated as options. Also, POSIX requires that unrecognized options be diagnosed as “illegal”, but since they are not really against the law the default is to diagnose them as “invalid”. POSIXLY_CORRECT also disables _N_GNU_nonoption_argv_flags_, described below. _N_GNU_nonoption_argv_flags_ (Here N is grep's numeric process ID.) If the ith character of this environment variable's value is 1, do not consider the ith operand of grep to be an option, even if it appears to be one. A shell can put this variable in the environment for each command it runs, specifying which operands are the results of file name wildcard expansion and therefore should not be treated as options. This behavior is available only with the GNU C library, and only when POSIXLY_CORRECT is not set.
Po zalogowaniu się do systemu, znajdujemy się w katalogu domowym użytkownika, o tym świadczy znak tyldy ~ widoczny po nazwie komputera i dwukropku:
damian@ubuntu:~$ Do poruszania się po strukturze katalogów, czyli tak właściwie do zmiany lokalizacji, w jakiej się w danym momencie znajdujemy wykorzystać możemy polecenie cd Wykonanie samego polecenia, bez żadnych argumentów spowoduje przejście do katalogu domowego użytkownika za każdej, dowolnej lokalizacji.
Podstawowym argumentem tego polecenia są dwie kropki, a wykonanie takiej składni:
cd .. skutkować będzie przejściem do jednego katalogu wyżej w strukturze katalogów. Kolejny, często używany argument w tym poleceniu to /, zwany ukośnikiem, który pozwala nam z każdego, dowolnego miejsca w strukturze katalogów przenieść się do katalogu głównego dysku:
cd / cd pozwala oczywiście na poruszania się po strukturze w nieco bardziej elastyczny sposób aniżeli tylko przechodzenie do katalogu nadrzędnego czy domowego. Dzięki niemu możemy za pomocą jednej linii kodu przenieść się w dowolne miejsce w strukturze, bez względu na to gdzie aktualnie się znajdujemy, np. takie polecenie: cd /etc/apm spowoduje przejście do katalogu apm, znajdującego się w katalogu etc
Innym trywialnym, ale również bardzo ważnym i potrzebnym narzędziem jest ls
ls jest to program listujący zawartość danego katalogu. Żadna filozofia, ale polecenie bardzo często stosowane. Samo w sobie zwraca nam zawartość katalogu, w jakim aktualnie się znajdujemy, nic jednak nie stoi na przeszkodzie, aby wylistować zawartość zupełnie innego katalogu znajdującego się w zupełnie innej lokalizacji, np. wykonanie takiego polecenia:
ls /etc/apt Wylistuje nam zawartość katalogu apt
Do dyspozycji mamy sporo parametrów polecenia ls Do najważniejszych z całą pewnością zaliczyć należy parametry a oraz l, gdzie a pozwala nam wyświetlić cała zawartość katalogu łącznie z plikami ukrytymi, linkami czy archiwami:
damian@ubuntu:~$ ls -a
. .bash_history .bashrc .config email kontakty pliki rok2019 .selected_editor .zarobki .. .bash_logout .cache dane .gnupg .local .profile rok2020 .sudo_as_admin_successful
a l, który już doskonalone znacie z poprzedniego odcinka pozwala na listowanie zawartość wraz z dodatkowymi informacjami takimi jak uprawnienia, własność, wielkość czy datę utworzenia pliku czy katalogu: damian@ubuntu:~$ ls -l
total 16 drwxrwxr-x 2 damian damian 4096 Feb 3 11:04 dane -rw-rw-r-- 1 damian damian 0 Feb 3 11:04 email -rw-rw-r-- 1 damian damian 0 Feb 3 11:04 kontakty drwxrwxr-x 2 damian damian 4096 Feb 3 11:04 pliki drwxrwxr-x 2 damian damian 4096 Feb 3 11:04 rok2019 drwxrwxr-x 2 damian damian 4096 Feb 3 11:04 rok2020
Parametry można oczywiście ze sobą łączyć.
Z ciekawszych, moim zdaniem opcji programu znaleźć możemy chociażby sortowanie, dzięki czemu wyświetlić sobie możemy listę posortowaną według np. czasu utworzenia danego zasobu:
ls -la --sort=time
Nie rzadziej niż zmiana pozycji w strukturze katalogów czy listowanie zawartości, przydają nam się w codziennej pracy z systemem narzędzia służące do budowania struktury katalogów. Jednym z takich narzędzi jest program mkdir, które to w całej swojej prostocie pozwala na tworzenie pojedynczych katalogów, całych zbiorów katalogów, a także daje możliwość zdefiniowania miejsca, gdzie dany katalog czy zbiór ma zostać utworzony. Wydanie takiego polecenia:
mkdir podana_nazwa_katalogu tworzy nam katalog o podanej nazwie w lokalizacji, w jakiej się w danym momencie znajdujmy. Jeśli taki katalog chcielibyśmy utworzyć w innym miejscu, w innej lokalizacji, to wcale nie musimy do niej przechodzić. Wystarczy, że wydamy polecenie mkdir, a jako argument wpiszemy całą, bezwzględną ścieżkę, łącznie z nazwą. Takie polecenie np:
mkdir /home/bolek/katalog123 utworzy nam katalog o nazwie katalog123, znajdujący się w katalogu domowym użytkownika o nazwie bolek
UWAGA!Jeśli podczas tworzenia zasobu pojawi się monit o braku uprawnień, to pamiętajcie, że zawsze możecie temu zaradzić stosując frazę sudo przed poleceniem. Tworzenie pojedynczych folderów to sprawa prosta i oczywista, ale działanie mkdir nie ogranicza się tylko do tworzenia pojedynczych elementów tego typu. Dzięki niemu możemy również nadawać już na etapie tworzenia zasobu uprawnienia, tworzyć całe struktury katalogów za pomocą pojedynczej lini kodu, czy też tworzyć wiele katalogów jednocześnie. Do nadawanie uprawnień na etapie tworznia katalogu wykorzystujemy paramter m, natomiast do tworznia całych struktur, parametr p. Przykładowo, wykonanie takiego polecenia:
mkdir -m 755 nazwa_katalogu spowoduje utworzenie katalogu o podanej nazwie wraz z uprawnieniami.
Takie polecenie z kolei:
mkdir k1 k2 k2 utworzy nam trzy katalogi (k1, k2, k3) jednocześnie. Jeśli chcemy utworzyć cała strukturę katalogów, stosujemy parametr p, a także ukośniki / oraz klamrowe nawiasy {}, przykładowo takie polecenie:
mkdir -p dokumenty/{2018/{faktury,umowy,pliki},2019/{faktury,umowy,dane},2020/{faktury,umowy}}
Utworzy nam taką strukturę katalogów:
Ukośnik (/) pozwala nam tworzyć kolejny poziom katalogów, a nazwy katalogów na danym poziome, podajemy po przecinku w klamrowym nawiasie. Jeśli chcemy tworzyć nazwy kilku członowe dla katalogów to bierzemy je w cudzysłów albo stosujemy apostrofy, np: mkdir "zupa romana"
Nie rzadziej niż zmiana pozycji w strukturze katalogów czy listowanie zawartości, przydają nam się w codziennej pracy z systemem narzędzia służące do budowania struktury katalogów.
Jednym z takich narzędzi jest program mkdir, które to w całej swojej prostocie pozwala na tworzenie pojedynczych katalogów, całych zbiorów katalogów, a także daje możliwość zdefiniowania miejsca,
gdzie dany katalog czy zbiór ma zostać utworzony. Wydanie takiego polecenia:
mkdir podana_nazwa_katalogutworzy nam katalog o podanej nazwie w lokalizacji, w jakiej się w danym momencie znajdujmy.
Jeśli taki katalog chcielibyśmy utworzyć w innym miejscu, w innej lokalizacji, to wcale nie musimy do niej przechodzić. Wystarczy, że wydamy polecenie mkdir,
a jako argument wpiszemy całą, bezwzględną ścieżkę, łącznie z nazwą. Takie polecenie np:
mkdir /home/bolek/katalog123utworzy nam katalog o nazwie
katalog123, znajdujący się w katalogu domowym użytkownika o nazwie bolek
sudo przed poleceniem.
Tworzenie pojedynczych folderów to sprawa prosta i oczywista, ale działanie mkdir nie ogranicza się tylko do tworzenia pojedynczych elementów tego typu. Dzięki niemu możemy również nadawać już na etapie tworzenia
zasobu uprawnienia, tworzyć całe struktury katalogów za pomocą pojedynczej lini kodu, czy też tworzyć wiele katalogów jednocześnie. Do nadawanie uprawnień na etapie tworznia katalogu wykorzystujemy paramter m,
natomiast do tworznia całych struktur, parametr p.
Przykładowo, wykonanie takiego polecenia:
mkdir -m 755 nazwa_katalogu
spowoduje utworzenie katalogu o podanej nazwie wraz z uprawnieniami.
Takie polecenie z kolei:
mkdir k1 k2 k2utworzy nam trzy katalogi (k1, k2, k3) jednocześnie.
Jeśli chcemy utworzyć cała strukturę katalogów, stosujemy parametr p, a także ukośniki / oraz klamrowe nawiasy {}, przykładowo takie polecenie:
mkdir -p dokumenty/{2018/{faktury,umowy,pliki},2019/{faktury,umowy,dane},2020/{faktury,umowy}}
Utworzy nam taką strukturę katalogów:

Jeśli chcemy tworzyć nazwy kilku członowe dla katalogów to bierzemy je w cudzysłów albo stosujemy apostrofy, np:
mkdir "zupa romana"
Umiejętność tworzenia katalogów to jedno, czasami przydaje się również możliwość tworzenia plików, chociażby do testów czy labowania. Narzędzi w Linux'ach pozwalających tworzyć pliki jest naprawdę sporo, kiedy jednak chcemy utworzyć pusty plik, bez zawartości, najlepiej sprawdzi się polecenie touch
Analogicznie do omawianych wcześniej poleceń, również touch domyślnie tworzy plik w lokalizacji, w jakiej się znajdujemy, takie polecenie np:
touch nazwa.txtutworzy nam plik
nazwa z rozszerzeniem txt w lokalizacji, w jakiej się obecnie znajdujemy.
Takie polecenie natomiast:
touch dokumenty/2018/faktura1.txt
utworzy nam plik o nazwie faktura1 z rozszerzeniem txt w katalogu 2018
Jeśli chcielibyśmy, aby utworzony przez nas plik był plikiem ukrytym, przed jego nazwą podajemy kropkę, np. takie polecenie:
touch .ukryty.txtutworzy nam ukryty plik o nazwie
ukryty z rozszerzeniem txt
Kopiowanie danych, kolejna prosta czynność, a jak często stosowana i wykorzystywana. W Linux'ach do kopiowania plików i katalogów wykorzystać możemy polecenie cp. Składania tego polecenia jest bardzo prosta i składa się tak naprawdę z 3 elementów: polecenia, nazwy (plus ewentualnie lokalizacji pliku lub katalogu) oraz miejsca docelowego. Takie polecenie np:
cp dokumenty/2018/faktura1.txt zupa
Przekopiuje plik faktura1.txt, znajdujący się w lokalizacji dokumenty/2018 do katalogu zupa, znajdującego się w lokalizacji bieżącej.
cp ma kilka ciekawych opcji. Jedną z nich jest możliwość zmiany nazwy pliku w nowej lokalizacji, już na etapie przenoszenia. Jeśli wydamy takie polecenie:
cp dokumenty/2018/faktura1.txt zupa/nowa_faktura1.txt
plik faktura1.txt zostanie przekopiowany do katalogu zupa, z jednoczesną zmianą nazwy na nowa_faktura1.txt
cp służy nie tylko do kopiowania plików, ale również całych katalogów. Aby jednak przekopiować zawartość danego katalogu do nowej lokalizacji, musimy użyć parametru r, który pozwala na kopiowania całych struktur katalogów, nie tylko plików. Wykonanie takiego polecenia np:
cp -r dokumenty romana/kopia_dokumenty
spowoduje skopiowanie zawartości katalogu dokumenty do katalogu kopia_dokumenty znajdującego się w katalogu romana
Inny ciekawy parametr polecenia cp to u, który kopiuje tylko te pliki, które zostały zmienione od daty ostatniej kopii. Wykonanie takiego polecenia np:
cp -ru dokumenty romana/kopia_dokumenty
przekopiuje tylko pliki zmienione, zmodyfikowane od czasu wykonania ostatniej kopii.
A teraz mały hack. Jeśli chcemy przekopiować cała zawartość bieżącego katalogu, to możemy zamiast nazwy czy też ścieżki użyć po prostu kropki. Kropka w powłoce bash oznacza aktualny katalog, tak więc jeśli chcemy skopiować cała zawartość lokalizacji, w jakiej się znajdujemy możemy wykonać np. takie polecenie:
cp -r . /cala_kopia
Analogicznie do polecenia cp kopiującego pliki i katalogi działa polecenie mv, które owe pliki i katalogi przenosi. Jego składnia jest dokładnie taka sama jak przy poleceniu cp. Pamiętać musicie tylko o tym ze cp tworzy kopie, a mvprzenosi zasoby z jednej lokalizacji do innej.
Z puli prostych, banalnych i oczywistych pleceń do omówienia pozostano nam jeszcze jedno, a mianowicie polecenie usuwanie pliki i katalogi, czyli rm. Polecenie samo w sobie może nie jakieś spektakularne, ale przy okazji jego omawiania wprowadzimy sobie dodatkowe hacki ułatwiające pracę. Zacznijmy od składni, jest banalna, wystarczy wpisać:
rm nazwa_plikui tyle, plik o podanej nazwie zostanie usunięty.
Jeśli chcemy usunąć katalog lub zbiór katalogów, to do polecenia musimy dodać parametr r. Takie polecenie np:
rm -r dokumentyusunie podany katalog wraz z całą jego zawartością.
Oczywiście usuwać możemy nie tylko całe zbiory katalogów, ale również pojedyncze katalogi znajdujące się głęboko w strukturze. Wykonanie takiego polecenia np:
rm -r dokumenty/2018/*usunie zawartość tylko katalogu
20182018. Gwiazdka oznacza właśnie wszystko z tego katalogu.
Generalnie gwiazdka ma bardzo fajne zastosowanie w systemie ponieważ oprócz tego, że oznacza wszystko, działa również jak każdy, dowolny znak.
Załóżmy ze chce usunąć z katalogu dokumenty folder zawierający w swojej nazwie np. liczbę 9. Wykonanie takiego polecenia np:
rm -r dokumenty/*[9]
Spowoduje, ze usunięty zostanie tylko katalog z liczbą 9 w nazwie.
Oczywiście w takim kwadratowym nawiasie zapisać sobie możecie inny dowolny ciąg znaków i wówczas polecenie zostanie wykonane tylko dla tych plików i katalogów, które w swoich nazwach mają przynajmniej jeden podany znak. Pamiętacie tym, ze w Linuksach wielkość liter ma znaczenia. Plik o takiej nazwie zocha, to nie to samo co plik o nazwie Zocha, to również musicie brać pod uwagę podając argumenty kwadratowym nawiasie.
Sytuację da się również odwrócić, jeśli np. przed liczbą 9 damy sobie ptaszka czyli znak^ to wówczas zostaną usunięte wszystkie podkatalogi, z wyłączeniem tych, w których nazwach pojawia się liczba 9. Wykonanie takiego polecenia np:
rm -r dokumenty/*[^9]
Usunie wszystkie podkatalogi zapisane w katalogu dokumenty poza katalogami z liczbą 9 w nazwie.
Polecenia można oczywiście dowolnie sobie komplikować. Takie np:
rm -r dokumenty/*[89]/*[k]*Usunie tylko katalogi o nazwie zawierającej literę k, znajdujące się w katalogu z liczbą 8 lub 9.
Kropki, gwiazdki, znaki zapytania i kwadratowe nawiasy stosować możecie w większości poleceń związanych z plikami czy katalogami, szczególnie przydatne są przy pisaniu skryptów.
Podstawowe polecenia związane z plikami i katalogami mamy już omówione. Przejdźmy teraz do poleceń zdecydowanie ciekawszych i bardzo przydatnych. Pierwszym z nich będzie diff, którego zadaniem jest porównywanie zawartości plików oraz katalogów.
Jestem przekonany, że co do użyteczności takiego narzędzia nikogo nie potrzeba przekonywać, wystarczy wyobrazić sobie sytuacje kiedy mamy dwa, podobnie wyglądające pliki z jedną, może kilkoma drobnymi różnicami, które musimy wychwycić. Bez narzędzia porównującego dane zawarte w plikach lub katalogach niejednokrotnie zadanie takie może okazać się bardzo czasochłonne. Mnie osobiście bardzo ostatnio przydał się ten sofcik, bo musiałem przekopiować wiele tysięcy plików z jednej lokalizacji do drugiej, a potem zweryfikować czy aby na pewno wszystko o się przekopiowało i wówczas diif okazał się zbawienny, bo okazało się, że kilka istotnych plików nie zostało przekopiowanych. Działanie programu pokażę na nieco mniejszym plikowo przykładzie, plików nie będzie kilka tysięcy, ale to nie ma znaczenia. Na dysku mam dwa katalogi wraz z podkatalogami i plikami:

Już na pierwszy rzut oka widać, że nieco się od siebi różną. Dzięki programowi diff i takiemu poleceniu:
diff -r dokumenty/ kopia_dokumenty/
Można sprawdić jakie pliki zapisane są tylko w jednym katalogu:
Only in dokumenty/2018/faktury: faktura3_2018.txtOnly in dokumenty/2018/faktury: faktura4_2018.txt
Diff doskonale sprawdzi się również w sytuacji, kiedy chcemy porównać zawartość dwóch plików. Załóżmy, że w jednym pliku mamy zapisany taki tekst:
test
test
test
a w drugim taki:
test
test
test1
Niby podobne, ale jednak subtelna różnica jest. Wykonanie takiego polecenia:
diff plik1 plik2
da nam taki wynik:
3c3
< test
---
> test1
a dzięki temu dowiemy się, że w pierwszym pliku, w linii 3 mamy słowo test, a w pliku drugim w trzeciej linii słowo test1
Kiedy interesujący nas plik posiada rozszerzenie, np: .txt .png .jpeg .mp3 łatwo możemy zorientować się czy jest to plik tekstowy, graficzny czy jakikolwiek inny. Bywa jednak czasami, iż plik takiego rozszerzenia nie posiada i wówczas bez specjalistycznej wiedzy czy oprogramowania nie jesteśmy w stanie dowiedzieć się co to za plik.
Korzystając z powłoki systemu linux'owego możemy skorzystać z ciekawego narzędzia, jakim jest file, które to pozwala nam odczytać informacje o podanym pliku. Wystarczy wykonać polecenie:
file nazwa_pliku
aby łatwo odczytać informacje zapisane w metadanych podanego pliku. Dane odczytane z przykładowych plików:
file plik1
wynik:
plik1: Audio file with ID3 version 2.3.0, contains:MPEG ADTS, layer III, v1, 320 kbps, 44.1 kHz, Stereo
file plik2
wynik:
plik2: PNG image data, 1920 x 1080, 8-bit/color RGBA, non-interlaced
file plik3
wynik:
plik3: Microsoft Word 2007+
W systemach opartych na jądrze Linux, cała konfiguracja zarówno samego systemu jak i oprogramowania, oparta jest o pliki konfiguracyjne oraz o wyniki ich działania, które również zapisywane są w plikach. Kiedy chcemy odczytać zawartość jakiegoś pliku bez wprowadzania w nim zmian, nie musimy używać do tego edytora czy to mcedit, nano czy vim, a możemy skorzystać z narzędzia cat. Ten program ma wiele zastosowań, a jednym z podstawowych jest właśnie odczytywanie zawartości plików. Wykonanie takiego polecenia np:
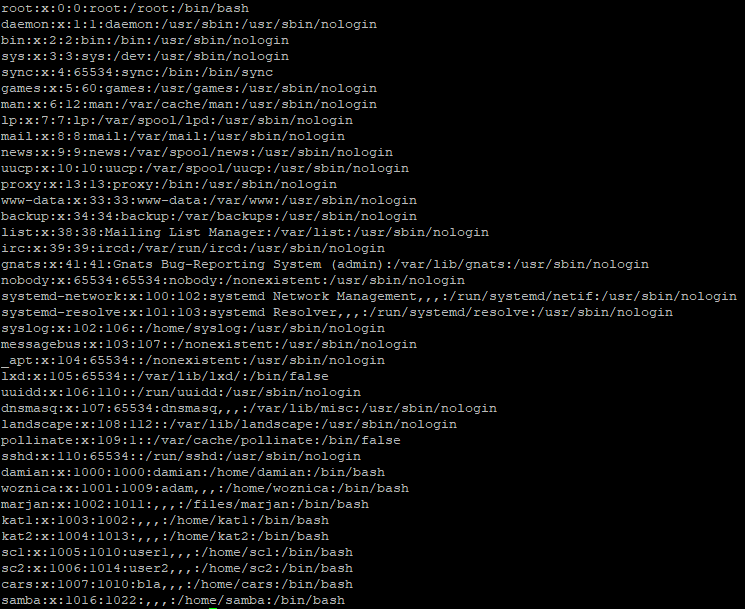
cat /etc/passwdwyświetli zawartość pliku, w którym zapisywane są podstawowe informacje o użytkownikach systemu Linux:
Cat pozwala nam również wyświetlać dane z wielu plików jednocześnie. Wystarczy, że jako argument polecenie podamy po kolei nazwy plików, których zawartość chcemy wyświetlić, np:
cat plik1 plik2 plik3
Wynik polecenia wyświetla połączoną zawartość plików:
zawartosc pliku pierwszego
zawartosc pliku drugiego
zawartosc pliku trzeciego
Strumieniowanie to bardzo często stosowana technika podczas pracy z systemem Linux. Polega ona na przekierowaniu dowolnej informacji z wejścia lub wyjścia w inne miejsce czyli do innego polecenia, programu lub też pliku.
Wejściem może być np. znak wpisany z klawiatury, a wyjściem to co dane polecenie czy program wyświetli na ekranie. Przykład? Polecenie ip a, które wyświetla konfigurację adresów IP. To co zobaczymy na ekranie po jego wykonaniu to właśnie wyjście.
Podstawowy przykład działania strumieni zobrazować można z wykorzystaniem polecenia, które poznaliśmy w poprzednim wpisie, a mianowicie cat. Załóżmy, że chcemy zapisać jakąś informację, jakiś dowolny tekst do pliku. Do tego wykorzystamy właśnie program cat, a także przekierowanie stronienia danych wejściowych, danych wpisanych z klawiatury do pliku. Wykonanie takiego polecania:
cat > plik1
Uruchomi możliwość wprowadzenia dowolnego tekstu z klawiatury. Zapiszmy coś takiego:
tekst wpisany z klawiatury
Edycję kończymy wybierając kombinację CTRL + D na klawiaturze.
To co wpisaliśmy, ten tekst: tekst wpisany z klawiatury czyli dane wejściowe, zostały przekierowane do pliku o podanej nazwie. Mówiąc prościej tekst podany z klawiatury został zapisany do pliku.
Kolejne dane do tego pliku? Nie ma problemu, pamiętać musimy tylko o tym, iż dodanie kolejnych danych wejściowych o tego samego pliku wymaga już podwojenia znaku większości. Takie polecenie:
cat >> plik1
Ponownie uruchomi możliwość dodania tekstu do pliku, w którym już co jest zapisane. Podajemy teskt:
kolejna linia tekstu
Teraz w naszym pliku znajdują się już dwie linie tekstu:

Jeśli w podanym przykładzie nie zastosowalibyśmy podwójnego strumienia, podwojonego znaku większości dane zostały by nadpisane, a nie dodane.
Przykładów zastosowania strumieni jest wiele, podczas administrowania systemem korzysta się z tej technik bardzo często. Wykonanie np. takiego polecenia:
chage -l damian > dane_hasla_damian
Spowoduje zapisanie informacji o ustawieniach hasła usera damian do pliku o nazwie dane_hasla_damian. W tym przypadku dane zwrócone przez polecenie chage -l damian zostają przekierowane strumieniem > do pliku o nazwie dane_hasla_damian
Po wykonaniu polecenia cat dane_hasla_damian te informacje nam się wyświetlą:

W kolejnych wpisach pojawi się więcej przykładów przekierowania strumienia danych z wykorzystaniem wielu inny poleceń.
Kolejne fajne i przydatne narzędzie powłoki systemu Linux to grep. Myślę, że nie ma na świecie admina pracującego na co dzień z Linux’em, który nie używałby tego programu. Grep służy do wyszukiwania i wyodrębniania w plikach określonego ciągu znaków tekstu. Zobaczmy przykład, takie polecenie:
cat /proc/cpuinfo
wyświetla mi informację o procesorze:
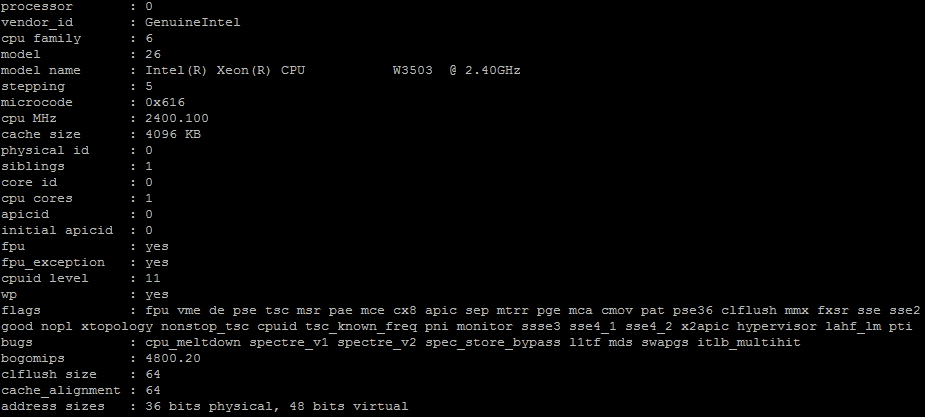
Dużo tego, a mnie interesuje np. tylko model procesora. Za pomocą polecenia grep i frazy model mogę sobie taką informację odfiltrować:
grep model /proc/cpuinfo
Wynik jak widzicie uwzględnia szukaną frazę, a nie całą zawartość pliku:

W przypadku wyszukiwania warto korzystać z parametru i, który nie zwraca uwagi na wielkość liter, a jak już wspomniałem kilkukrotnie Linux rozróżnia wielkość liter i jeśli nie użyjecie parametru i, a szukane słowo napisane jest z wielkiej litery, a w poleceniu zapiszemy słowo z małej to wynik będzie błędny. Jeśli chcemy oprócz modelu wyświetlić sobie powiedzmy jeszcze ilość rdzeni to też nie ma problemu, możemy użyć więcej niż jednego argumentu wyszukiwania, pamiętając, że szukane frazy należy rozdzielać kombinacją \|, a także zawrzeć w apostrofach. W takim przypadku nasze polecenie będzie wyglądało tak:
grep -i 'model\|core' /proc/cpuinfo
a jego wynik prezentuje się tak:

Inne zastosowanie polecenia grep? No jest ich cała masa, możemy np. sprawdzić czy w systemie jest użytkownik o danej nazwie:
grep -i damian /etc/passwd
albo wyszukać w logach systemowych interesującą nas usługę:
grep -i ssh /var/log/syslog
Za pomocą grep’a możecie również przeszukiwać całe katalogi, nie tylko pojedyncze pliki, wystarczy użyć parametru R. Takie polecenie np:
grep -R raz .
Wyszuka słowa raz we wszystkich plikach znajdujących się w bieżącej lokalizacji.
W tym wpisie zajmiemy się programem banalnym w założeniu, ale bardzo ciekawym w użytkowaniu i obszernym w możliwości. Programem tym jest find czyli sztandarowa wyszukiwarka plików i katalogów.
Program cechuje się sporą liczbą parametrów, które możemy wykorzystywać przy wyszukiwaniu. Raczej nikogo nie zaskoczy fakt, iż wyszukiwać możemy pliki po nazwach czy typie, ale już pewnie część będzie zaskoczona, że pliki również wyszukiwać można np. po czasie od daty ich ostatniej modyfikacji, po uprawnieniach czy właścicielu. Poniżej przedstawiam kilka przykładów użycia:
Wyszukanie plików i katalogów w lokalizacji bieżącej, które w swojej nazwie zawierają frazę dan:
find . -iname 'dan*'
Wyszukanie plików w lokalizacji bieżącej, wyłącznie z rozszerzeniem txt:
find . -iname '*.txt'
Wyszukanie wyłącznie plików w lokalizacji bieżącej, które w swojej nazwie zawierają frazę dan:
find . -iname 'dan*' -type f
Wyszukanie wyłącznie plików w katalogu domowym użytkownika damian, które w swojej nazwie zawierają frazę dani zostały zmodyfikowane w ciągu ostatnich 31 dni:
find /home/damian -iname 'dan*' -type f -mtime -31
Wyszukanie wyłącznie plików w katalogu domowym użytkownika damian, które w swojej nazwie zawierają frazę dan, zostały zmodyfikowane w ciągu ostatnich 31 dni, a ich właścicielem jest użytkownik stefanz jednoczesnym wylistowaniem za pomocą polecenia ls:
find /home/damian -iname 'dan*' -type f -mtime -31 -user stefan -ls
find można łączyć tworząc zapytanie wielowarunkowe, można również paramterów używać pojedynczo!
Możliwości programu find nie kończą się tylko na wyszukiwaniu plików czy katalogów. Korzystając z parametru exec możemy wykonywać całkiem sporą liczbę operacji na wyzyskiwanych zbiorach. Możemy je np. usunąć, skopiować do nowej lokalizacji, zmienić ich właściciela czy uprawnienia, a nawet odczytać interesujące nas informacje zawarte w tych plikach łącząc wyniki wyszukiwania ze znany już z poprzedniego wpisu poleceniem grep.
Zacznijmy od polecenia, które odnajdzie w bieżącej lokalizacji tylko pliki, które mają w swojej nazwie literę d, a następnie zmieni uprawnienia tych plików na 777:
sudo find . -iname 'd*' -type f -exec chmod 777 {} \;
root’a, dlatego należy w takim przypadku wykonać to polecenie na prawach sudo
Na końcu polecenia użyty został ciąg znaków {} \;. To ważne, aby o nim nie zapominać ponieważ jest to element konieczny przy stosowaniu parametru exec.
No to teraz polecenie, które odnajdzie w bieżącej lokalizacji tylko pliki, które mają w swojej nazwie literę d, a następnie przekopiuje te pliki do katalogu kopia (co ważne ten katalog musi istnieć!):
find . -iname 'd*' -type f -exec cp {} kopia \;
Ostatni przykład wykorzystania parametru exec to połączenie go ze znanym już nam poleceniem grep. Załóżmy, że chcemy odnaleźć ze zbioru plików, których nazwa rozpoczyna się na literę d, zapisanych w bieżącej lokalizacji frazę model. Nasze polecenie wówczas będzie wyglądało tak:
find . -iname 'd*' -type f -exec grep -i 'model' {} \;
Mam nadzieje, że każdy kto trafił na ten wpis, jest już na tyle ogarnięty informatycznie, że wie czym są archiwa. Dla tych co jednak nie wiedzą to powiem, że archiwum to nic innego jak karton do którego spakowaliśmy garnki, talerze i sztućce, aby łatwiej je przechować lub przenieść w inne miejsce… wróć, to nie artykuł na blaga kulinarnego, tylko tutorial z Linuxa więc jeszcze raz. Archiwum to paczka, która zawiera zbiór katalogów i plików, widoczna dla systemu operacyjnego jako jeden obiekt, jeden plik, tworzony po to aby łatwiej był nam je przechowywać czy przenosić, a także zabezpieczać. Znacie paczki 7zip czy innego Winrar’a? To są właśnie archiwa, do których zapakowano pliki. Archiwizację stosuje się w celu łatwiejszego przechowywania i porządkowania danych. Archiwa są często również bazą kopii zapasowych danych firmowych czy instytucjonalnych, a także za ich pomocą dystrybuowane jest czasami oprogramowanie. Jeśli chcemy np. zainstalować na Linuchu WordPress’a, to możemy to zrobić właśnie za pomocą archiwum. Nie wiem czy pamiętacie szczegóły z poprzedniego odcinka, tam również pojawił się temat archiwizacji. Podczas usuwania usera z systemu można jednocześnie stroszyć kopię jego danych zapisanych w katalogu domowym, takie kopia zapisywana jest na dysku właśnie jako archiwum.
Z archiwizacją jednoznacznie łączy się również pojęcie kompresji, czyli zamiany sposobu zapisu danych na nośnikach w taki sposób, aby zajmowany one mniej miejsca niż zbiór źródłowy. Sposoby kompresji danych w systemie Linux, również w tym wpisie zaprezentuje.
W Ubuntu, jak i w wielu innych dystrybucjach opartych na jądrze Linux występuje kilka narzędzi, programów do zarządzania archiwami, najpopularniejsze to tar oraz zip. Dla większości użytkowników ich działanie jest do siebie zbliżone, zasadnicza różnica jest taka, że tar sam w sobie nie obsługuje kompresji, a zip już tak. Oczywiście da się archiwum tar również skompresować, ale do tego wykorzystywane są zewnętrzne narzędzia takie jak gzip czy bzip.
Tyle teorii, teraz nieco praktyki. Dzisiaj omówimy sobie narzędzie tar wraz z jego podstawowymi opcjami ponieważ jest to domyślny program do zarządzania archiwami instalowany na Linux’ach. Zaczniemy od prostego zadania, a mianowicie wykonamy sobie archiwum z katalogu z nazwie dokumenty:
tar -cf archiwum_dokumenty.tar dokumenty
gdzie: tar rozpoczyna tworzenie archiwum, c tworzy archiwum, f pozwala nadać nazwę z rozszerzeniem: archiwum_dokumenty.tar, a dokumenty to katalog z plikami, na bazie którego wykonujemy archiwum. Oczywiście tworzymy archiwum w bieżącej lokalizacji, można również podać nazwę wraz z pełną ścieżką jeśli chcielibyśmy utworzyć archiwum z katalogu, który zapisany jest w innym miejscu.
Jeśli podczas tworzenia archiwum, chcemy zobaczyć jakie pliki są do tego archiwum dodawane, możemy dodać parametr v, wówczas nasze polecenie będzie wyglądało tak:
tar -cvf archiwum_dokumenty.tar dokumenty
A co jeśli tak zajdzie konieczność udokumentowania tego co do archiwum wrzuciliśmy? Nic trudnego, możemy skorzystać przecież ze znanego już nam przekserowania strumienia. Zakładając, że info o tym co jest w archiwum chcemy zapisać do pliku dok_arch nasze polecenie będzie wyglądało tak:
tar -cvf archiwum_dokumenty.tar dokumenty > dok_arch
Oczywiście nawet jeśli nie zrobiliśmy dokumentacji tego co jest w archiwum na etapie jego tworzenia, to zawsze możemy do niego zajrzeć korzystając z parametru t. Wówczas nasze polecenie będzie wyglądało tak:
tar -tf dok.tar
Dodanie kolejnego pliku lub katalogu do archiwum? Prosta sprawa, wystarczy skorzystać z parametru r, podać nazwę archiwum z rozszerzeniem, a także lokalizację z nazwą pliku. Wówczas nasze polecenie może wyglądać np. tak:
tar -rf dok.tar dokumenty/2020/faktura12_2020.txt
a do naszego archiwum zostanie dodany plik faktura12_2020.txt
Jak już mówiłem tar sam w sobie nie obsługuje kompresji, można jednak korzystając z tego programu i odpowiednich parametrów wymusić skompresowanie archiwum za pomocą „zewnętrznego” oprogramowania do kompresji, m.in. gzip. Załóżmy, że chcemy utworzyć skompresowane archiwum z katalogu dokumenty. Użyć do tego możemy takiego polecenia:
tar -czf dok.tar.gz dokumentygdzie parametr
z umożliwia skompresowanie archiwum za pomocą oprogramowania gzip. Ważne, aby nowotworzone archiwum miało rozszerzenie .tar.gz
Jeśli z jakiś powodów nie chcemy kompresować archiwum na etapie jego tworzenie lub też otrzymaliśmy paczkę, którą chcemy dopiero kompresować to łatwo możemy to wykonać stosując polecenie gzip, z nazwą archiwum, które chcemy skompresować:
gzip dok.tarWówczas automatycznie utworzony zostaje plik z rozszerzaniem
.tar.gz, a archiwum z samym rozszerzaniem .tar znika.
Dekompresję, czyli działanie odwrotne do kompresji wykonać możemy stosując polecenie gunzip wraz z nazwą skompresowanego archiwum:
gunzip dok.tar.gz
Umiemy już archiwa tworzyć i je kompresować, to zobaczmy teraz jak rozpakować archiwum. Do tego użyć możemy parametru x, a całe polecenie może wyglądać tak:
tar -xf dok.tar
Domyślnie tar rozpakowuje archiwa do katalogu, w którym archiwum było zapisane. Jeśli chcemy do oczywiście możemy określić inną lokalizację do rozpakowania archiwum, pod warunkiem oczywiście, że taka istnieje. Do tego użyć możemy parametru C. Takie polecenie np:
tar -xf dok.tar -C /Home/stefanRozpakuje archiwum do katalogu domego usera
stefan
Ostatnia kwestia jak zajmiemy się w tej serii wpisów będą linki zwane dowiązaniami. Sprawa dość prosta jeśli chodzi o samą mechanikę jak i praktyczne wykorzystanie. Czym są linki no to generalnie każdy z Was powinien już wiedzieć. W ogólnym pojęciu link wskazuje na jakiś inny obiekt, plik lub jego zawartość.
W systemach Linux występują dwa rodzaje dowiązań, linków: twarde oraz symboliczne. Dowiązanie twarde tworzy nową nazwę dla zasobu, zapisując ją w nowej lokalizacji (nie kasując poprzedniej), a sam link nie odwołuje się do pliku samego w sobie, ale tylko do jego zawartości.
Brzmi tajemniczo natomiast jest proste w działaniu. Załóżmy, że mamy plik o nazwie plik.txt z zawartością:
teskt1 teskt2 teskt3
Wykonajmy teraz dowiązanie do tej zawartości, zapisane w katalogu o nazwie link. Polecenie wyglądało będzie tak:
ln plik.txt link/link_do_plik.txtgdzie
ln to polecenie uruchamiające tworzenie dowiązania, plik.txtto nazwa zasobu, do którego tworzymy dowiązanie, a link_do_plik.txt to nazwa dowiązania. Od teraz ten nowy plik zawiera te same dane co plik źródłowy, a my utworzyliśmy sobie nową nazwę do zasobu
teskt1 teskt2 teskt3
Jeśli usuniemy plik źródłowy, czyli plik.txt, to ten nowy plik, czyli link_do_plik.txt pozostanie na dysku wraz z zawartością.
W przypadku drugiego rodzaju dowiązań, zwanych symbolicznymi, sprawa jest dużo prostsza, te dowiązania w swoim działaniu są bardzo podobne do skrótów jakie znamy chociażby z systemu Windows. Wskazują one zwyczajnie na jakiś plik. Skasowanie pliku źródłowego spowoduje, że link, dowiązanie, po prostu przestanie działać prawidłowo. Podobnie z resztą jak skrót w Windowsie.
Utwórzmy teraz dowiązanie symboliczne do pliku o nazwie plik2.txt. Możemy to zrobić np. tak:
ln -s plik2.txt kat/nowy_plik2.txt
Kiedy wyświetlimy zawartość katalogu, w którym zapisaliśmy dowiązanie miękkie, to zobaczymy na jaki plik wskakuje nam link:
lrwxrwxrwx 1 damian damian 9 Feb 24 12:23 nowy_plik2.txt -> plik2.txt
Skasowanie pliku źródłowego wiązać się będzie oczywiście z tym, że taki link przestanie nam działać.
Zastosowanie dowiązań jest bardzo powszechną praktyką na systemach opartych na jądrze Linux. Ja ostatnio korzystałem z tego rozwiązania konfigurując serwer webowy Apache, tam włączanie poszczególnych modułów może odbywać się właśnie za pomocą dowiązań.
Jak działa tryb NAT w VirtualBox już wiemy. NAT to ustawienie, które symuluje ruter. Kiedy karta maszyny wirtualnej działa w trybie NAT, program VirtualBox staje się dla wirtualnej maszyny wirtualnym ruterem i dzięki temu ma ona dostęp do Internetu, zakładając oczywiście, że taki dostęp ma komputer lokalny na którym VirtualBox działa. Analogiczna sytuacja jak fizyczny ruter i urządzenia w sieci lokalnej, tylko tutaj sprawę załatwia nam soft. Jeśli chcemy przy takim trybie pracy karty sieciowej wirtualnej maszyny łączyć się z nią poprzez SSH, musimy skonfigurować dla tej karty przekierowanie portu (ang. port forwarding).
Wyjaśnienie czym jest przekierowanie portu (portów) oprzemy o typowy dla tego problemu przykład. W sieci lokalnej pracują 4 komputery z prywatnymi adresami IP. Na jednym z nich, skonfigurowano serwer WWW, który hostuje stronę. Do neta urządzenia mają dostęp poprzez ruter, który po stronie zewnętrznej (po stronie sieci Internet) ma publiczny adres IP. Na tym ruterze dział usługa NAT czyli translacja adresów sieciowych prywatnych na publiczne i odwrotnie. Dzięki "natowaniu" urządzenia w sieci lokalnej mogą komunikować się z Internetem. Gdyby NAT nie działał, no to komunikacja byłaby niemożliwa, bo przecież urządzenia mają prywatne adresy, a jak wiemy po necie śmigamy stosując adresy publiczne.

Jak zatem wyświetlić stronę na urządzeniu, które pracuje w innej sieci niż sieć lokalna, np. z poziomu Internetu? Potrzebny do tego będzie publiczny adres IP rutera. Pomijamy tutaj oczywiście usługę DNS. Pojawia się pytanie: skoro w sieci LAN pracują 4 urządzania, to skąd wiadomo, że ruch przychodzący z Internetu, przychodzący przecież na publiczny adres rutera, który żąda wyświetlania strony ma być kierowany do konkretnego komputera, który hostuje stronę, a nie do jakiegoś innego? No tutaj dochodzimy do wspomnianej techniki przekierowania portu. W dużym skrócie: jest to usługa, która pozwala wskazać naszemu ruterowi, do jakiego urządzenia w sieci lokalnej i na jakim porcie ma kierować ruch związany z żądaniami WWW, które przychodzą z innych sieci, w tym wypadku z Internetu. Po odpowiedniej konfiguracji żądanie, które odbiera ruter, jest dalej kierowane do serwera, który hostuje stronę.
Podsumowując: jeśli żądanie strony WWW trafi do rutera na jego publiczny adres, ten przekseruje ruch WWW do właściwego komputera, bo ma w swojej konfiguracji informacje, że dany, konkretny komputer w jego sieci lokalnej jest serwerem WWW.

Oczywiście przekierowanie nie dotyczy tylko usługi WWW, przekierować porty można dla każdej usługi jaka w sieci pracuje, oczywiście również SSH. Praktycznie każdy nowoczesny ruter posiada wbudowany mechanizm przekierowania i nie ma wielkiej filozofii w jego konfiguracji. Przekierowanie portu lub też portów, bo można to robić dla wielu usług jednocześnie, jest w VirtualBox bardzo proste. Wystarczy uruchomić ustawienia zaawansowane karty NAT wirtualnej maszyny, wybrać przekierowanie portu i podać dane widoczne poniżej:

Nazwa jest dowolna, nie ma znaczenia, a protokół warstwy transportowej to TCP, bo SSH działa na właśnie TCP. W polu IP hosta możemy wpisać adres pętli zwrotnej, czyli 127.0.0.1, wówczas tylko z naszego fizycznego kompa będzie można połączyć się z serwerem i to ten adres wykorzystamy do połączenia. Jeśli chcemy aby można było się łączyć z serwerem również z innych komputerów w sieci LAN to należy zostawić to pole puste. W polu Port hosta podajemy port po jakim nasz komputer będzie komunikował się z VirtualBox, można tutaj podać port domyślny dla SSH czyli 22, ale tylko pod warunkiem, że na naszym fizycznym kompie nie pracuje już serwer SSH, który tego portu by używał.
Można tutaj podać również jakikolwiek inny numer portu, jeśli jest nie jest na systemie lokalnego komputera zajęty. Jaki porty są zajęte, a jakie wolne można sprawdzić wydając polecenie netstat -a w terminalu. Numer jaki tutaj wpiszecie należy zapamiętać, bo potrzebny będzie do połączenia. IP gościa jest puste, bo adres na tej karcie wirtualna maszyna ma z wirtualnego serwera DHCP tak więc VirtualBox będzie wiedział po jakim IP ma się połączyć. Port gościa to natomiast 22, bo na tym pracuje SSH no i tutaj wyjątków już nie ma.
Do połączeń terminalowych poprzez SSH w Windows 10 można użyć CMD albo PowerShell, zakładając, że zainstalowana jest funkcja klienta SSH, można to sprawdzić wchodząc w ustawienia systemu i dalej aplikacje. Można też w terminalu wydać polecenie ssh, jeśli wyświetli się pomoc dla tego polecenia to znaczy ze klient SSH działa. Do połączeń można też oczywiście wykorzystać zewnętrzne oprogramowanie. Najpopularniejszym klientem SSH jest PuTTY, który możecie sobie za darmo pobrać ze strony projektu, nie trzeba go nawet instalować, wystarczy uruchomić.
Po odpowiedniej konfiguracji możemy już połączyć się zdalnie z wykorzystaniem CMD lub PowerShell wydając takie polecenie:
ssh nazwa_użytkownika_w_ubuntu@127.0.0.1 -p 22Domyślnie podczas tworzenie użytkownika w Ubuntu tworzona jest również grupa o takiej samej nazwie oraz identyfikatorze (id). Jeśli chcemy możemy oczywiście tworzyć również inne grupy, a następnie dodawać do nich użytkowników. Do zarządzania grupami użytkowników wykorzystać możemy polecenia: addgroup (dodające grupę) lub delgroup (usuwające grupę). Zmiany z wykorzystaniem tych poleceń zapisywane są w pliku /etc/group
Dodanie nowej grupy:
sudo addgroup nazwa_grupyDodanie nowej grupy z identyfikatorem 2000:
sudo addgroup nazwa_grupy --gid 2000Usunięcie grupy:
sudo delgroup nazwa_grupyHasła użytkowników Ubuntu zapisywane są w pliku /etc/shadow. Plik ten zawiera zaszyfrowane hasła użytkowników (domyślnie hasła szyfrowane są z wykorzystaniem algorytm SHA2), a także informacje związane z czasem ich ważności czy dacie ich ostatniej zmiany. Informacje zwarte w pliku shadow da się również wyświetlić i modyfikować za pomocą polecenia chage.
Wyświetlenie ustawień hasła użytkownika:
sudo chage -l nazwa_użytkownikaWymuszenie zmiany hasła użytkownika:
sudo chage -d 0 nazwa_użytkownikaUstawienie data wygaśnięcia konta:
sudo chage -E rok-miesiąc-dzień nazwa_użytkownikaUstawienie ilości dni ważności hasła licząc od daty zmiany hasła:
sudo chage -M ilość_dni nazwa_użytkownikaUstawienie ilości dni przed datą wygaśnięcia hasła, kiedy system zacznie informować użytkownika o tym, że jego hasło niedługo wygaśnie:
sudo chage -W ilość_dni nazwa_użytkownikaDo zmiany hasła użytkownika można wykorzystać również polecenie passwd, które również stosowane jest do modyfikacji haseł. Jeśli chcemy zresetować hasło użytkownika można to zrobić wydając takie polecenie:
sudo passwd nazwa_użytkownikaParametry można łączyć. Wszystkie opcje danego polecenia zawsze wyświetlimy wydając polecenie z parametrem h.
Domyślnie w systemie Ubuntu można nadawać hasła składające się przynajmniej z 6 znaków. Nie ma natomiast konieczności stosowania haseł złożonych, czyli taki, które muszą składać się np. przynajmniej z jednej cyfry, dużej litery czy znaku specjalnego (!, @, $,*, itp.). Jeśli chcemy wymusić stosowanie dłuższych haseł oraz wymagań co do złożoności to musimy doinstalować pakiet libpam-pwquality.
Możemy to zrobić wydając takie polecenie:
sudo apt install libpam-pwqualityPo instalacji, edytujemy plik z ustawieniami tego pakietu (tutaj przez edytor mcedit):
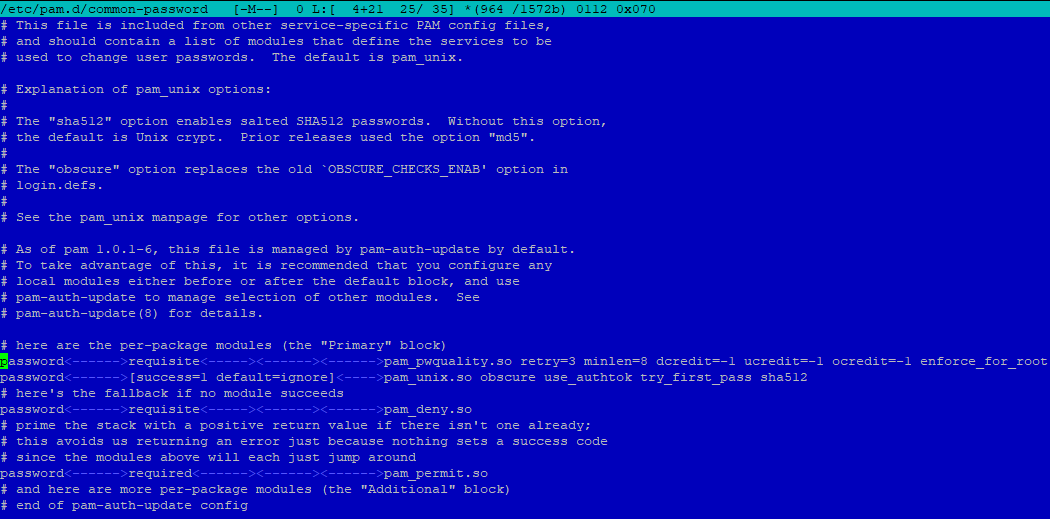
sudo mcedit /etc/pam.d/common-passwordna końcu linii 25 możemy dopisać następujące parametry:
minlen – określający minimalną długość hasła, np. minlen=8dcredit – wymuszający zastosowanie cyfr, np. dcredit=-1lcredit – wymuszający zastosowanie małych liter, np. lcredit=-1ucredit – wymuszający zastosowanie wielkich liter, np. ucredit=-1ocredit – wymuszający zastosowanie znaków specjalnych, np. ocredit=-1Aby system nie przyjmował haseł niespełniających zadanych wymagań, po takich ustawieniach były by tylko monity ze hasła nie spełniają reguł, ale i tak byłyby przyjmowane, musimy jeszcze dopisać na koniec linii enforce_for_root.
Przykład konfiguracji widać poniżej, zakłada ona stosowanie 8 znaków w haśle, przynajmniej jedną cyfrę, przynajmniej jedną wielką literę oraz przynajmniej jeden znak specjalny:
Włączenie tego pakietu powoduje również, że zablokowane jest podawanie haseł które zawierają następujące po sobie znaki np. qwerty123 – takie hasło nie zostanie przyjęte.
Niedozwolone jest również stosowanie w haśle nazw użytkowników, jeśli przykładowo mamy w systemie użytkownika bolek, to nie możemy ustawić dla niego hasła bolek.
Projektując politykę haseł w firmowej sieci warto pomyśleć czy nie ustawić również opcji, która pozwoli zapisywać historię tworzonych haseł, a także uniemożliwi stosowanie kilku zastosowanych poprzednio. Dla użytkowników to zmora, ale dla osób dbających o bezpieczeństwo środowiska IT super opcja. Dla przykładu skonfigurujmy sobie hasła tak aby system pamiętał 5 zastosowanych wcześniej, a dzięki temu nie pozwoli na użycie tych samych przez 5 kolejnych zmian.
Zaczynamy od utworzenia pliku (jeśli nie istnieje), który przechowa nam zaszyfrowane, stare hasła. Plik ten powinien znajdować się w lokalizacji
/etc/security a jego nazwa to opasswd. Tworzymy plik:
sudo touch /etc/security/opasswdNastępnie musimy przekazać własność pliku root'owi, zrobimy to wykonują takie polecenie:
sudo chown root:root /etc/security/opasswdNa koniec jeszcze ustawiamy dla pliku takie uprawnienia:
sudo chmod 600 /etc/security/opasswdTeraz ponownie edytujemy plik common-password, znajdujący się w lokalizacji /etc/pam.d:
sudo mcedit /etc/pam.d/common-passwordW linii 26, po frazie pam_unix.so dodajemy opcję remember i przypisujemy dla niej wartość liczbową odpowiadającą ilości pamiętanych haseł, u nas będzie to 5:
remember=5
Zapisujemy zmiany w pliku i od teraz nasze ustawienia haseł powinny działać.
Temat w porównaniu do systemów windowsowych można powiedzieć łatwy, prosty i przyjemny, bo w odróżnieniu od systemów z Doliny Krzemowej, w Ubuntu oraz we wszystkich innych dystrybucjach Linux, występują tylko 3 uprawnienia. Są nimi odczyt, zapis oraz wykonanie, a przypisuje się je pojedynczo lub zbiorczo odpowiednio do właściciela (user-owner), grupy (group) nadrzędnej, jakiej właściciel jest członkiem oraz do pozostałych (others), czyli wszystkich innych użytkowników niebędących właścicielami zasobu lub członkami grupy będącej właścicielem.
Przy nadawaniu uprawnień stosuje się albo zapis słowny, stanowiący skrót od tych trzech uprawnień: read (r), write (w), execute (x) lub też zapis liczbowy stanowiący sumę liczba odpowiadających za dane uprawnienie; 4 to odczyt, 2 to zapis, a 1 to wykonanie. Pełne uprawnienia to 7, gdyż to suma tych trzech liczb. Dla wielu system liczbowy jest bardziej intuicyjny do stosowania aniżeli zapis literowy, sami oceńcie, który dla Was jest wygodniejszy.
Uprawnienia do danego pliku lub też katalogu wyświetlimy stosując polecenie ls -l
drwxrwxr-x damian damian 4096 Nov 5 08:38 katalog1d – to oznaczenie katalogurwx – pełne prawa dla właścicielarwx – pełne prawa dla grupyr-x – prawa do odczytu i wykonania dla pozostałych, brak prawa do zapisuTakie uprawnienia oznaczają, że użytkownik będący właścicielem katalogu (tutaj damian) oraz jego grupa mają pełne prawa, a pozostali mogą jedynie odczytywać zawartość katalogu, bez możliwości tworzenia w nim zasobów.
Do modyfikacji uprawnień stosuje się polecenie chmod
Przykłady użycia (zapis literowy):
Dodanie pozostałym (others) prawa do zapisu w katalogu/pliku:
sudo chmod o+w nazwa_katalogu/pliku (lub ścieżka)Odebranie właścicielowi (user) prawa do wykonania (x), z jednoczesnym odebraniem grupie (group) prawa do odczytu (r) w katalogu/pliku:
sudo chmod u-x,g-r nazwa_katalogu/pliku (lub ścieżka)Jednoczesne nadanie pełnych praw dla wszystkich (all):
sudo chmod a+rwx nazwa_katalogu/pliku (lub ścieżka)Jednoczesne odebranie pełnych praw dla wszystkich (all):
sudo chmod a-rwx nazwa_katalogu/pliku (lub ścieżka)Uprawnienia wykorzystując notację literową nadajmy poszczególnym użytkownikom (u – właściciel, g – grupa, o – pozostali, a – wszyscy) z plusem i odpowiemy literami odpadającymi uprawnieniom (r – odczyt, w – zapis, x – wykonanie), zabieramy natomiast minusem. Stosując notację literową zawsze modyfikujemy istniejące ustawienia, nie zmieniając pozostałych.
Pełne prawa dla wszystkich w katalogu/pliku:
sudo chmod 777 nazwa_katalogu/pliku (lub ścieżka)Pełne prawa dla właściciela (4+2+1), prawa do odczytu i zapis dla grupy (4+2) oraz tylko odczyt (4) dla pozostałych w katalogu/pliku:
sudo chmod 764 nazwa_katalogu/pliku (lub ścieżka)Pełne prawa dla właściciela (4+2+1), prawa do odczytu dla grupy (4) oraz brak uprawnień (0) dla pozostałych w katalogu/pliku:
sudo chmod 740 nazwa_katalogu/pliku (lub ścieżka)Jednoczesne odebranie pełnych praw dla wszystkich:
sudo chmod 000 nazwa_katalogu/pliku (lub ścieżka)Nadając uprawnienia poprzez notację liczbową zawsze nadpisujemy poprzednie ustawienia.
Zmiana właściciela pliku czy katalogu to dość częsta praktyka. Domyślnie właścicielem pliku czy katalogu jest użytkownik, który go stworzył. Jeśli zaistnieje potrzeba zmiany właściciela wykorzystujemy do tego polecenie chown
Zmiana właściciela pliku lub katalogu:
sudo chown nazwa_użytkownika nazwa_katalogu/pliku (lub ścieżka)Zmiana grupy pliku lub katalogu:
sudo chown :nazwa_grupy nazwa_katalogu/pliku (lub ścieżka)Jednoczesna zmiana właściciela i grupy:
sudo chown nazwa_użytkownika:nazwa_grupy nazwa_katalogu/pliku (lub ścieżka)Oprócz trzech rodzajów uprawnień, czyli odczytu, zapisu i wykonania, mamy jeszcze do dyspozycji w systemach opartych na jądrze Linux, tak zwane bity specjalne. Są nimi tak zwany lepki bit (t), a także user ID (SuID - u), oraz group ID (GuID - g). Dla zwyczajnych zjadaczy chleba, najistotniejsze jest działania lepkiego bitu, gdyż ma on bardzo fajne zastosowanie. Załóżmy, że mamy katalog, w którym pliki zapisuje kilku użytkowników. Muszą oni mieć prawa zapisu do tego katalogu, bo inaczej nie będą mogli w nim tworzyć zasobów. To jednak niesie za sobą pewne zagrożenie. Otóż, jeśli mają prawa do zapisu, no to mogą też usuwać zawartość, nawet jeśli nie są właścicielem. Konsekwencje mogą być takie, że poszczególni użytkownicy mogą sobie wzajemnie, umyślnie lub też nieumyślnie kasować zasoby. Lepki bit działa tak, że zabrania usuwania zasobów, których użytkownik nie jest właścicielem. Lepki bit można ustawić wydając polecenie:
sudo chmod a+t nazwa_katalogu/pliku (lub ścieżka)Wówczas, do już nadanych uprawnień dopisany zostanie lepki bit. Można również dodać lepki bit podczas nadawanie uprawnień. Przykładowo jeśli wszyscy mają mieć pełna prawa do danego zasobu z jednoczesnym dodaniem lepkiego bity można polecenie wykonać tak:
sudo chmod 1777 nazwa_katalogu/pliku (lub ścieżka)Jedynka od lewej strony to przypisanie lepkiego bitu. Po dopisaniu lepkiego bitu w uprawnieniach pojawia się na końcu litera t:
drwxrwxrwt 2 damian damian 4096 Nov 5 08:38 katalog1Innym specjalnym rodzajem bitu jest GuID. Działa on tak, że nadaje identyfikator grupy właściwa katalogu wszystkim nowo utworzonym katalogom, bez względu na to kto je tworzy. Dzięki temu wszystkie nowoutworzone zasoby będą miały identyfikator grupy właściciela katalogu nadrzędnego. Jest to opcja przydana kiedy na jednym katalogu pracuje kilku użytkowników, który nie są oni członkami danej grupy, a chcemy aby katalogi, które tworzą miały prawa, nadane dla grupy właściciela. GuID możemy również przypisać na dwa sposoby:
sudo chmod g+s nazwa_katalogu/pliku (lub ścieżka)lub
sudo chmod 2777 nazwa_katalogu/pliku (lub ścieżka)Po nadaniu bitu specjalnego GuID w uprawnieniach katalogu/pliku, na którym wykonaliśmy polecenie prawo do wykonania dla grupy (x) zmieniło się na S:
drwxrwsrwx 2 damian damian 4096 Nov 5 08:38 katalog1Podobnie działa ostatni bit specjalny o nazwie SuID. Kiedy nadajmy taki bit dla pliku, no to wówczas user, który go wykonuje, może to być jakiś skrypt na przykład, robi to na prawach właściciela, a nie na swoich. Analogicznie, SuID możemy przypisać na dwa sposoby:
sudo chmod u+s nazwa_katalogu/pliku (lub ścieżka)lub
sudo chmod 4777 nazwa_katalogu/pliku (lub ścieżka)Po nadaniu bitu specjalnego SuID, w uprawnieniach katalogu/pliku, na którym wykonaliśmy polecenie prawo do wykonania dla właściciela (x) zmieniło się na S:
drwsrwsrwx 2 damian damian 4096 Nov 5 08:38 katalog1Mechanizmy bitów specjalnych GuID oraz SuID należy stosować z rozwagą, bo jeśli zostaną użyte w sposób nieprzemyślany to niewłaściwi użytkownicy mogą mieć pełne prawa do plików katalogów, a nie zawsze tego chcemy.
Omawiając tematykę uprawnień nie sposób nie wspomnieć o mechanizmie ich dziedziczenia. W przeciwieństwie do systemów Windows, w Ubuntu oraz innych systemach opartych na jądrze Linux, domyślnie zjawisko dziedziczenia uprawnień nie występuje. To znaczy pliki i katalogi, które tworzone są w zasobie z określonymi uprawnieniami takich samach uprawnień nie będą mieć. Każdy pliki i katalog tworzony w katalogu domowym użytkownika ma uprawnienia domyślne 775 dla katalogów oraz 664 dla plików. W przypadku katalogu domowego użytkownika ROOT, a także katalogu głównego, uprawniania są ustawione na 755 dla katalogów oraz 644 dla plików. Jeśli chcemy, aby nowo tworzone zasoby w danym katalogu miały inne uprawniania no to możemy zastosować mechanizm zwany umask. Umask definiuje domyślne uprawnienia dla zasobów tworzonych w katalogu.
Jeśli chcemy sprawdzić jaką maskę mamy ustawioną w danym katalogu, wykonujemy po prostu polecenie umask. W przypadku umask mamy do czynienia z odwrotnością liczb określających uprawnienia. Jeśli maska jest ustawiona na 0002 to znaczy, że właściciel ma pełne prawa do zasobu (0002: od 7 odjęto 0, co daje 7), analogicznie grupa (0002: od 7 odjęto 0, co daje 7), a pozostali mają odczyt i wykonanie (0002: od 7 odjęto 2 co daje 5). Pierwsze0 od lewej strony to bity specjalne, ich tutaj nie bierzemy pod uwagę. W przypadku plików uprawnienia domyślne są na poziomie 664, bo domyślnie dla plików systemy z jądrem Linux nie dają prawa execute przy tworzeniu, tak więc pomimo ustawionej maski pliki domyślnie mają uprawnienia 664. Maskę oczywiście można zmodyfikować wydając polecenie umask.
Pełne uprawnienia dla wszystkich:
umask 000Pełne uprawnienia dla właściciela, dla grupy oraz pozostałych brak uprawnień:
umask 077Pełne uprawnienia dla właściciela, grupy, dla pozostałych brak uprawnień:
umask 007Pełne uprawnienia dla wszystkich, dla grupy tylko odczyt i wykonanie, dla pozostałych tylko odczyt:
umask 026Jeśli ustawimy konkretną maskę dla katalogu i w tym katalogu utworzymy kolejne podkatalogi to tutaj dziedziczenie będzie działać, ale tylko jeśli podkatalogi będzie tworzył użytkownik, który ustawił maskę, bo co ważne maska nie jest ustawieniem dostępnym dla innych użytkowników. To znaczy, że kiedy na tym katalogu będzie pracował inny użytkownik to dla niego maska nie będzie taka jak ustalił użytkownik tworzący katalog (właściciel), tylko domyślna. Należy o tym pamiętać! Ustawiona maska działa też tylko podczas aktywnej sesji, to znaczy jeśli użytkownik zamknie połączenie i zaloguje się ponownie to maska powróci do domyślnych uprawnień.
Pojawia się teraz pytanie czy da się zrobić tak, aby zawsze nowo tworzone zasoby w jakimś katalogu miały te same prawa dla wszystkich użytkowników. No pewnie, jest to możliwe i co ważne bardzo często używane. Chmod to bardzo stary system nadawania uprawnień. Nieco mało elastyczny i przy bardziej zaawansowanych ustawieniach czy zadaniach niesprawdzający się zbyt dobrze. Na szczęście istnieje również bardziej rozbudowany systemu uprawnień oparty na listach kontroli dostępu do plików i katalogów (setfacl).
Jeśli chcemy skonfigurować katalog tak, aby wszystkie tworzone w nim zasoby miały, np. zawsze pełne prawa dla wszystkich no to możemy wykonać takie polecenia:
chmod 777 nazwa_katalogu (lub ścieżka)a dalej
setfacl –R –d –m u::rwx nazwa_katalogu (lub ścieżka)